Technical systems audit
Docs Planning
Table of contents
- Aim of this document
- Summary
- Hosting
- Routing requests
- URL persistence
- Managing URLs
- Current Content Management tools
- Authentication / user login
- Internationalization
- Search
- Version control
- Deployment
Aim of this document
This document contains an overview of the technical infrastructure and technical challenges we have to deal with as part of the W3C website redesign project. It aims to summarise a number of discussions between Studio 24 and the W3C Systems Team, and research undertaken by Studio 24, and will help provide the background and context for future technical work on this project.
Summary
The W3C have been managing their own website infrastructure for three decades. During this time a range of different technologies have been used and different strategies have been used for URL structures. The result is over 2 million web pages built in static HTML, Perl, PHP, CMSs such as WordPress, and custom systems built in Symfony. Web content is stored in CVS, modern systems such as GitLab and GitHub, and databases via CMS tools such as WordPress and custom Symfony tools.
This creates many challenges for the W3C team in managing this web content effectively.
The majority of web pages sit under the URL www.w3.org
The new W3C website needs to sit alongside this large family of other web pages. It’s important to ensure the new website pages are easy to maintain for W3C.
The key findings are:
- Preferred tech stack for the new web pages is Debian Linux, Nginx or Apache, MySQL and PHP
- Varnish is used for full-page caching
- HAProxy is used for load balancing
- Symfony is the preferred PHP web framework
- There is a lot of flexibility on URLs due to the use of HAProxy to forward URLs based on path
- A key challenge is URL management. Due to decades of growth and W3C’s Cool URIs Don’t Change philosophy a full URL history has been retained. Managing this, however, is cumbersome and complex and has created a fair amount of technical debt. This is especially difficult where old and new web content share the same URL space (e.g. new WAI site and old WAI pages).
- W3C are open to changing URLs and redirecting old URLs where appropriate, where this makes sense to do so.
Hosting
W3C has a large-scale hosting setup hosted in Cambridge, MA, USA. Around 100 servers running Debian Linux (Debian stable) hosted on MIT’s OpenStack. There are around 20-30 servers related to the primary web site www.w3.org
Tech stack summary:
- HAProxy is used for load balancing
- Varnish HTTP Cache is used for full-page caching
- Debian Linux
- Apache is used for the webserver serving the static content
- Nginx and PHP-FPM is used for the webserver for Symfony and WordPress
- MySQL for database storage
- Symfony is the preferred PHP framework used in W3C (using PHP-FPM and Nginx)
- WordPress for News/Blogs and Community site (using PHP-FPM and Nginx)
The new website will sit on new webservers so W3C are flexible on the software we can install (e.g. PHP 7.4).
Routing requests
HAProxy is used for load balancing and this allows W3C to forward requests matching URL paths to different backend servers. Primary backend server targets include WordPress blog, MediaWiki, GitHub pages static site, dynamic pages created with Symfony (powered by Nginx), static documents (around 2.8 million resources).
Web pages are cached using Varnish.
As a rough overview incoming web requests look like:

URL persistence
W3C is committed to a policy of persisting URLs, informed by Tim Berners-Lee’s article Cool URIs don’t change and the official W3C URI Persistence Policy.
The W3C URI Persistence Policy states the following resources should always remain available:
- The home page “https://www.w3.org/”;
- Those which start “https://www.w3.org/” immediately followed by four decimal digits;
- Those which start “https://www.w3.org/TR/” immediately followed by four decimal digits;
- Those which start with “https://www.w3.org/ns/”.
The result of these policies is W3C has treated all pages on w3.org as follows:
- Don’t delete anything
- Don’t change old URLs
Managing URLs
Due to never changing URLs and the inevitable organic evolution of the w3.org website the way URLs have been created has changed a lot over the years.
This has become extremely complicated to manage and can be illustrated through three key issues, which W3C would like advice on:
- Confusing URL structure for users
- Old pages sitting alongside new pages in the same URL space which are difficult to manage
- Huge number of redirects which are difficult to manage
While some URLs need to remain as they are, W3C is open to changing URLs of pages and setting up appropriate redirects.
Examples of the confusing URL structure
- Inconsistent use of .html extension on some pages but not others, e.g. https://www.w3.org/Consortium/facts.html
- Legacy pages with date-based URLs which do not reflect their last updated date, e.g. https://www.w3.org/2013/data/
- Different use of casing on many URLs, e.g. https://www.w3.org/Consortium/Member/List
https://www.w3.org/Consortium/fees
Examples of old pages sitting alongside new pages
This often means new web pages have URLs that share the same space as old, legacy web pages. For example, the WAI website is a static site generated by Jekyll via GitHub pages.
The WAI team wanted to retain their existing URL, so the new Jekyll site exists in the same URL space as the legacy files. In this example, the Jekyll-generated WAI site consists of about 800 files, while there are about 65,000 files in the legacy document tree under /WAI/.
New page: https://www.w3.org/WAI/fundamentals/
Old page: https://www.w3.org/WAI/IndieUI/
Initially, the static built Jekyll site was checked into CVS so it sits alongside the existing legacy content. This was not felt to be the best way to manage new content alongside legacy content. In addition, W3C would rather move away from CVS and automate this process.
Recently the W3C Systems Team have deployed a solution to managing the WAI site. This works in the following way:
- GitHub Action to build static website via Jekyll and deploy to GitHub Pages
- Generate a list of resources and push to W3C site via a simple web hook
- W3C then proxies requests for all these resources to GitHub Pages, avoiding the need to commit future updates of the WAI site to the old CVS repository
How URLs and redirects are currently managed
As noted above all page URLs are on www.w3.org, however, there are many different sites and services where URLs are managed:
- HAProxy config on the www.w3.org front end
- Apache config on the web mirrors
- Apache .htaccess files on the web mirrors
- Apache/nginx config on backend servers (Symfony, wikis, blogs)
There are 3,706 Apache .htaccess files with different rewrite rules. The rewrite rules have grown organically, are very difficult to manage and represent technical debt.
HAProxy takes responsibility for primary routing and redirects. However, URLs can then redirect again in local webserver configuration (e.g. Apache config or .htaccess files in the filesystem).
Where a large number of simple redirects are managed in HAProxy map files are used to help manage these.
W3C tried to create a new system to help manage redirects (restricted to members), though work on this has been paused while the new website redesign project takes place.
The volume of configuration to route w3.org URLs has become very large and difficult to manage. W3C would like to be able to empower staff to create simple redirects, while not allowing them to break the site.
If possible, W3C, would like advice on how to manage these more sensibly.
Example redirect config 1
An abbreviated summary of some HAProxy routing config:
acl sf_path path_beg /ieapp/ ... /Press/Articles
acl not_sf path_beg /Press/Articles- /Press/Articles.html
use_backend symfony if sf OR sf_path !not_sf
This is setup via “acl”, the format of which is:
acl [acl name] [criterion] [pattern 1] [pattern 2] ...
use_backend [backend name] [if and unless statements]
Criterion = path_beg (match beginning of path) and the patterns are the URL paths to match.
Example:
Symfony (symfony backend): https://www.w3.org/Press/Articles
Not Symfony (www-mirrors backend): https://www.w3.org/Press/Articles-2007.html
However, a .htaccess file redirects this URL via a 302 (temporary) redirect to https://www.w3.org/Press/Articles/2007
In fact all Press/Article type URLs redirect, so it would appear this rule may not be necessary.
Example redirect config 2
acl blogs path_beg /blog/
acl not-blogs path_reg ^/blog/(xmlsrv|ceo|BPWG|DDWG|MWITeam|MWInews|SWEO|powder|uwa-more|2015/04/tag-by-election-2015)
use_backend blogs if blogs !not-blogs
default_backend www-mirrors
Example:
WordPress blog (blogs backend server): https://www.w3.org/blog/
Not WordPress (www-mirrors backend): https://www.w3.org/blog/ceo/
However, this URL is again redirect via an .htaccess file to: https://www.w3.org/blog/category/ceo/
So this rule could be replaced with one redirect and no .htaccess file.
Another example: https://www.w3.org/blog/BPWG/
Does exist in CVS and is served as static HTML.
Use of subdomains
As noted above, the default rule is all core content for W3C is hosted on www.w3.org. W3C think about most web content as being part of the core site.
There are some exceptions to this rule, where websites host content that is not considered core W3C content a subdomain URL is used. For example: https://validator.w3.org/ and https://api.w3.org/
Current Content Management tools
The majority of pages on www.w3.org are not content managed in the traditional sense. Instead, a variety of systems and techniques are used to manage content on w3.org.
Current tools to manage page content include:
- Static HTML files
- WordPress blogs
- Symfony-built admin tool to manage content stored in a database
- Jekyll via GitHub pages
You can see where a page comes from by adding this string after the URL: ,source
For example:
Kept in CVS repository (static files)
https://www.w3.org/2020/02/pressrelease-studio-24-w3c-website-redesign.html.en,source
https://www.w3.org/Guide/,source
Proxied to GitHub pages site (content managed in GitHub pages / Jekyll)
https://www.w3.org/das/,source
We’ve noted below whether content is expected to be in scope or out of scope. This will be confirmed in the Information Architecture work.
WordPress
Two WordPress instances:
- blog/
- 25 sites
- Blog (958 blog posts according to the blog API) - in scope
- News (4,216 news posts according to the news API) - in scope
- Talks
- Then mostly working group blogs
- One test site
- community/
- Standalone WordPress site for Community Groups - out of scope
Static pages
Most pages in the 2008 style are either generated dynamically using Symfony (maintained) or statically via makefiles, XML, and XSLT (unmaintained).
Most content is managed as static HTML, edited via local editors (e.g. emacs, vi) or WYSIWYG application (e.g. Bluegriffon) and committed into CVS repository using CVS clients, HTTP PUT (e.g. when using Bluegriffon) or via WebDAV (e.g. Web folders on Windows).
W3C want to move away from this old method to something more modern, easier to content manage and more maintainable.
Homepage - in scope
The current homepage is a mix of generated HTML snippets. These are generated via PHP, XML and other tools. This enables the homepage (and other pages) to be generated from a mix of files reading in content from different sources.
How this works is detailed at https://www.w3.org/Web/Tools/ and https://www.w3.org/Web/HowTo/generator.html (restricted to members).
This is old legacy code, but the important thing is the summary of where content is generated from.
- News = read from WordPress /blog/news/
- W3C Blog = read from WordPress /blog
- W3C Member testimonial = read from Testimonials database (also displayed on https://www.w3.org/Consortium/Member/Testimonial/)
- Events = read from the Events Manager (also displayed on https://www.w3.org/participate/eventscal )
- Talks and appearances = read from WordPress /blog/talks/
GitHub pages - out of scope
Used for editors’ draft of W3C specifications, or sections of the W3C site managed by the community.
E.g.
https://w3c.github.io/ServiceWorker/v1/
https://www.w3.org/TR/2019/CR-service-workers-1-20191119/
Managed in https://github.com/w3c/ServiceWorker
And:
https://www.w3.org/Guide/
Managed in https://github.com/w3c/Guide
Technical Reports index page - in scope
Please note only the index page is in scope for this project, the Technical Report pages themselves are out of scope.
This is an example of a URL that cannot change and is covered by the W3C URI Persistence Policy.
This page is managed in Symfony, with content loaded from a database. While the frame of this page is expected to be in scope (header, footer) it is not necessary for the content of the page to be in scope.
W3C welcome feedback on this page, though this is not required.
Symfony database classes
There are two methods to read data stored in the new Symfony application.
There are Symfony PHP classes that can be used to read data directly from the database. Symfony is used to efficiently manage new pages and make changes
This method is used to generate the TR/ index page. Symfony PHP code is stored in a private git repo at GitLab which Studio 24 does not have access to.
More data is available via the PHP classes than via the REST API.
- DB description https://www.w3.org/Systems/db/db_w3c_description (restricted to members)
- PHPDoc for the Symfony entities: https://jay.w3.org/~jean-gui/phpdoc/
Symfony API
There is a REST API which can be used to make the Technical Reports content available (read-only access via API keys). The W3C Systems team maintain the API code.
- Code repo https://github.com/w3c/w3c-api
- Docs https://w3c.github.io/w3c-api/
- View API endpoints https://api.w3.org/doc
The following API endpoints need to be queried to return similar information as used on the current TR/ page.
https://api.w3.org/specifications
https://api.w3.org/specifications/html53
https://api.w3.org/specifications/html53/versions/20181018/editors (latest draft)
This exposes the data:
- Title
- Link to draft
- List of authors of draft
This does not include:
- Working group
- Tags (e.g. CSS)
Events - in scope
Events cover when W3C runs an event to engage with the community.
https://www.w3.org/participate/eventscal
Managed in an old tool https://www.w3.org/Web/Tools/Events/?show_past (restricted to members)
W3C are happy for this tool to be replaced, or for the W3C Systems Team to adapt this old system to add the new design styles.
Talks - in scope
Talks cover when individuals from the W3C community give talks.
Historically these are static pages: https://www.w3.org/2007/11/Talks/y2016.html
Since 2017, these are managed in WordPress: https://www.w3.org/blog/talks/events/
The events plugin used in WordPress for this content is difficult to use, it’s non-intuitive, and if WordPress is retained an alternative needs to be looked at.
Testimonials - in scope
Testimonials from W3C members.
https://www.w3.org/Consortium/Member/Testimonial/List
Legacy system, based on 3 different systems. Ideally this does need to move to a new system.
W3C have thought about moving this into the W3C Admin app, so it is linked to members data.
Symfony admin app
A Symfony admin application exists at: https://www.w3.org/admin/ (restricted to members)
This is used as the entry point for W3C backend applications written in Symfony.
This is used to manage:
- Users & Groups
- Press clippings (about W3C on external sites, front end “W3C in the Press”)
- Translations (frontend: “W3C Translations”)
- Meetings
- Web rewrites
W3C have recently published new Working Groups content which is intended to replace the following pages:
- https://www.w3.org/2000/09/dbwg/groups
- https://www.w3.org/Consortium/activities
- https://www.w3.org/2000/09/dbwg/groups
- https://www.w3.org/groups/
- https://www.w3.org/users/
- https://www.w3.org/Member/Groups
Authentication / user login
There are a variety of logins across the W3C site including basic authentication over HTTPS and session-based login via WordPress and MediaWiki. There is a desire to move towards a more unified login experience.
The Member login screens and account management pages are in scope for this project, but the wider Member area is not in scope.
Implementing any changes to the login process is out of scope for this project, however W3C would like input on the user journey for:
- New users signing up to get a W3C account
- New users requesting to join a Working Group
- Existing user logging in
W3C:
We are looking for advice here, not implementation, so would be happy to receive input from Studio 24 on how to rework our system. We would like our help on making the user journey smoother, especially for new users.
W3C would like the website redesign project to “consider user workflow including logged in/out states.”
There is a risk this will be out of scope due to the volume of work in this project. Studio 24 will review the project scope with W3C to confirm this.
Basic authentication over HTTPS
Example: https://www.w3.org/Member/ (restricted to members)
Simple basic authentication over HTTPS. This displays a basic browser dialog box to request the user’s login credentials. This is a pretty basic user interface, which is not an ideal user experience.
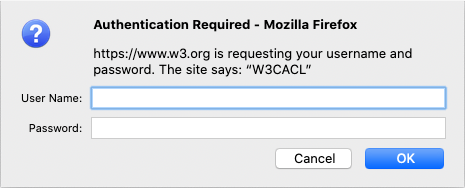
Application login using W3C credentials
Example: https://www.w3.org/community/wp-login.php (restricted to members)
Systems such as WordPress and Mediawiki are programmed to use the W3C user login credentials when logging in. These tools usually create a duplicate user in the child system, with login credentials tied to the W3C account.
Modern authentication system
Example: https://auth.w3.org/ (restricted to members)
There is a beta project designed to support better authentication using an authentication portal. This system supports two-factor authentication.
W3C are also looking into supporting WebAuthn. Also see WebAuthn Overview.
Internationalization
Localised web pages
At present a number of individual web pages are translated on the w3.org website.
Examples:
Press releases
https://www.w3.org/2019/12/pressrelease-wasm-rec.html.en
https://www.w3.org/2019/12/pressrelease-wasm-rec.html.fr
Technical reports
https://www.w3.org/Translations/WCAG20-zh/WCAG20-zh-20141009/
https://www.w3.org/Translations/
Country websites
W3C Offices are a regional arm of W3C to help recruit members and promote W3C technology.
Different W3C Offices around the world have set up local country websites, which include translations of various W3C web pages. These sites are managed by the individual W3C Offices. Some country sites use HTTPS, some are just on HTTP. Some sites are marked as archived, some are no longer online.
The content covered by country websites covers:
- Translated content from W3C site
- News / blog / press releases
- Other W3C content, e.g. Standards page
- Local content unique to the country site
- News
- Content, e.c. Contact us
- Talks (resources for talk given in the country, e.g. talk slides)
- Links back to the main W3C site
China
Last updated May, 2020.
This site is actively maintained. The Chinese site is in Simplified Chinese. The desire is to move this content to the main w3.org website and at a minimum have up-to-date homepage, top-level landing pages and latest news pages.
Content:
- This is the most custom of all country websites
- Translations and summaries of international news
- Local news
- Local versions of pages on the main W3 site
- Local content such as About
Japan
This site is not currently maintained. If a localized version of w3.org is set up for China, W3C would also like to see this done for Japan.
Content:
- Local content such as HTML5 interest group and how to join W3C.
Other country sites
There is a list of other attempts at localizing the W3C home page at: https://www.w3.org/Consortium/Offices/
How localised content is managed
At present this is done in a few different ways.
Static content, such as press releases, are simply added as separate HTML files with the language code within the filename.
Technical documents are translated manually by the W3C community. The list of these translated documents is managed in the Symfony admin app and details of how to manage this can be read at https://www.w3.org/Consortium/Translation/
The future of internationalization for W3C
There is a desire to use a more modern way to manage localised content.
W3C would like the Chinese web content to be part of the main w3.org website.
Languages W3C would like to see translated content for are:
- English (American English)
- Chinese (Simplified Chinese)
- Japanese
- French (less of a priority)
Expected content for localised versions of w3.org is:
- Homepage
- Top navigation links (e.g. Standards)
- News (translations of W3C news where available, it is unlikely this will cover all news items due to available time & resources)
- Local section (local only to country site)
- E.g. local news
- Local members
- Translations board
- Contribution board
- Local media
There is no agreement on exactly how this happens or what the URL format should be for localised web content. Current options include:
- Sub-site (e.g. cn.w3.org)
- Separate site (e.g. www.chinaw3c.org)
- Sub-folder path (e.g. w3.org/cn/)
- Path-based language (e.g. https://www.w3.org/Consortium/mission.zh, https://www.w3.org/Consortium/mission?lang=zh or similar)
A good summary of the requirements and thinking behind how to manage localised content appears on the China site migration into new W3C site page on the W3C wiki.
Search
The current site search for w3.org links to an external DuckDuckGo search. This search engine provider was chosen for its good reputation for data privacy.
Example search: https://duckduckgo.com/?q=site%3Aw3.org+css&search-submit=&ia=web
Search results pages are hosted on the DuckDuckGo website and according to their Partnerships page there are no custom site search options available due to copyright and data privacy reasons.
The DuckDuckGo search works well, however, does not offer a branded user experience.
It is clear no out-of-the-box search from a CMS would be suitable for the large volume of content on w3.org.
Some sub-sites offer search within that section only. These include:
- WAI - https://www.w3.org/WAI/search/?q=css (Tipue JavaScript search)
- Blog - https://www.w3.org/blog/?s=css (WordPress)
- News - https://www.w3.org/blog/news/?s=css (WordPress)
- Community - https://www.w3.org/community/?s=css (WordPress)
- Technical Reports - https://www.w3.org/TR/?title=css (custom JavaScript search)
Version control
W3C use GitLab for internal projects, including custom Symfony code used on the w3.org site. W3C use GitHub for public projects.
Historical content, mostly static but also includes PHP and Perl files, are stored in a CVS repository (restricted to members).
For the W3C redesign project Studio 24 will be granted access to git repos on W3C’s GitHub account.
Deployment
For development work W3C is happy to make a test server available for Studio 24, for which Studio 24 can have direct access. For development, Studio 24 can use any method to deploy. Our normal process is to use Deployer for simple deployments.
For staging, W3C can set this up and we can discuss whether Studio 24 need direct access or not. W3C use Puppet for deployment, the Systems Team will manage this.
The Systems Team requirements before deploying work is:
_W3C need full understanding of project and code and have control over it before deployment. _
W3C will control production deployments.
Hosting environments
Hosting is managed by the W3C Systems Team.
Development
The development environment will include experiments such as testing CMS options. Studio 24 will need access to the latest stable version of PHP and MySQL.
Once the main site is being built Studio 24 will use the Development server to host the test site, intended for use by Studio 24 and test partners to QA work.
Sites on the Development server should be private. Studio 24 will take responsibility for deploying code to Development.
Staging
The staging environment is used to host a test version of the site to be tested with the client (W3C).
It is expected the Private Beta will be hosted on the Staging server. After the beta moves to public beta it is still important to have a staging environment available to test new work before it is pushed to production.
Sites on the Staging server should be private. W3C Systems Team will take responsibility for deploying code to Staging.
Production
The production environment is used to host the public site.
The Beta site should be a fully-working operational W3C website (for the pages in scope for this project) and is available publicly.
We anticipate this being hosted on https://beta.w3.org and we would recommend linking to this from the current production website to encourage usage.
We recommend identifying the Beta site via a clear Beta banner which should encourage user feedback.
Sites on the Production server should be public. W3C Systems Team will take responsibility for deploying code to Production.
Beta site URL
The beta site can either be hosted on a URL such as beta.w3.org or on the main www.w3.org site with a mechanism to opt-in to viewing the beta version of the site.
beta.w3.org
- Clear separation of beta and production site.
- Hard-coded absolute links will send the user back to the production site. However, with the correct CMS setup absolute links should not exist on the new site.
- The last time W3C ran a beta site there was some cleaning up work required to remove old links to beta.w3.org
Opt-in to view beta on www.w3.org
- Same site URL, so absolute links will carry on working OK and nothing to clean up after launch.
- It will be impossible to convert all w3.org pages for Public Beta so may be confusing to users to go between production and beta on the same URL space. This could be minimised by the effective usage of a beta banner to make it clear when the user is on the beta site.
- Technically more complex to setup, W3C Systems Team suggested a cookie that HAProxy can then route requests to a new backend server.
- Caching needs to be carefully thought about, ideally production and beta pages would cache independently in Varnish (for example via Vary header).
Moving to Live
Once W3C is ready to launch the new site live, the process of moving to live is anticipated to be updates to HAProxy and the removal of the Beta banner.
Studio 24 recommends reviewing the launch plan with W3C Systems Team to ensure this process is smooth. Studio 24 will support the Systems Team during this critical phase.